
Politics I is a new work of participatory and web-based computer music that explores concerns about the audience as a political public. It has three movements, Digital Discourse, Cybernetic Republic, and Technoautocracy. For performances of this work, please get in touch at ec.lemmon@gmail.com
Table of Contents
About the Work
In western concert art music, the audience’s participation in the presentation of a musical work is traditionally restricted to a staid listening experience within a proscenium setting. Politics I aims to overhaul this rigid notion of music-making by breaking down the barriers between composers, performers, and the audience and rendering audible the politics of aesthetic preference that exists within participatory music settings. In this new computer music system, audience members submit a text, the text is processed by the system, and then depending on the movement, this textual ‘action’ impacts the music generated by the system in specific ways. Drawing on insights from musical semiology and political theory, I argue that this setting allows audience members to recognize the possible sonic effects of their own inputs and make choices that impact the aesthetic experience in real time. In effect, composer and audience thus determine the shape of Politics I together. Because this participatory setting provides the audience with agency to impact the musical work, the audience’s interactions give rise to an internal discourse contained within the domain of the participating individuals and their submitted texts. This discourse, in turn, generates a concert-going public that reflects a consensus-based, or rather, Habermasian public sphere [1]. Within the internal discourse of this public, audience members articulate a politics of aesthetic preference, wherein the sonic results that are preferred by more audience members can take precedence within the musical texture of the work.
The resulting politics of aesthetic preference is most easily recognizable through the interplay between groups vying to determine the shape and experience of the musical work, with the groups being generated through either spontaneous mimesis or pre-planned and coordinated action. To systematically analyze these discursive processes within the audience, and their potential to effect change within the music, the computer music system behind Politics I parses text messages submitted by the audience through an array of natural language processing (NLP) techniques in Python.[1] In SuperCollider, it then sonifies the analyzed content of the input messages while simultaneously displaying them visually. The system is customized to generate music such that distinct code-bases act as individual movements of a complete piece. Politics I has three distinct movements: ‘Digital Discourse’, ‘Cybernetic Republic’, and ‘Technoautocracy’. Each of these movements serves as an analogy to a particular political system, with the purpose of musically representing how systemic structures influence political decision-making but can also be subverted through coordinated action. The work is of variable length; it usually lasts at least 30 minutes, but can be up to 40 minutes long.
[1] A more detailed examination of these internal, aesthetic and political processes can be found in my recent article in Organised Sound, where I analyze Luke Dahl, Jorge Hererra and Carr Wilkerson’s TweetDreams.
[2] Here, text message is not meant as the common colloquial stand-in for an SMS, but rather a text-based message that comes from one of many different protocols or platforms for text-based communication.
Movements

Digital Discourse
This movement continuously generates short clips of music based on the contents of each individually submitted text. It mines texts for linguistic features to generate data for sonification. The system also senses changes in the ‘average’ topic discussed. For each 30-second time window, the work generates an average ‘topic’ value for the just concluded window and compares it to the average ‘topic’ value of the prior window. The difference between these two values then determines the number of chords and the rate by which the harmonic content of the work changes in the upcoming window.
Scored Version
As part of the testing process, I developed a scored version of this movement. The logic behind this was to concretely demonstrate the determinism of the system, with language features used as a system of control for sound synthesis parameters. You can find the score in the download link below:

Cybernetic Republic
In this movement, the audience votes on a select number of musical options that are then synthesized live in a series of rounds. Each ‘round’ has a voting period and a resting period. During the resting period, the options for the next round are displayed to the audience, and the audience is given a chance to listen to the result of the previous round’s selections. When a voting period ends, the highest vote-getter is selected for audio generation. Because musical textures are highly integrated with one another, the winning option may radically alter the music being generated. For example, changes to meter or harmonic progression may dramatically affect other layers of the musical texture. Alternatively, the changes may largely be unnoticeable.

Technoautocracy
In the final movement, the audience is given very little control over sonic results, and the system constantly wages both sonic and visual violence upon its members. If the audience expresses negative sentiment toward the sounds being produced through their submitted texts, the system will respond aggressively with loud sounds—but if negativity is expressed consistently, it will ultimately weaken. If a large majority of the audience members express sustained, negative sentiment toward the sounds produced, the ‘autocracy’ will collapse into an outro. Conversely, if enough audience members continue to express positive sentiments towards the music, or the audience is unable to organize and ‘defeat’ the system, the Technoautocracy will be sustained and culminate in a homogenous sound world.
Program Notes
Work Documentation
Digital Discourse
Live Version
In the live version of Digital Discourse, audience members are able to freely submit any text they like to generate sound. The work sample above is taken from the first live performance of the movement on February 8th, 2022 at Stony Brook University.
Linguistic Features and Sonification
Walking the Graph
Digital Discourse generates its harmonic motion by sonifying the distance between windowed, averaged similarity scores of the texts submitted by audience members. More concretely, the further the average similarity of texts submitted within a 30-second time frame is from average similarity of the texts submitted in the prior 30 seconds, the further the musical algorithm will step through a chord progression during the upcoming 30-second time frame.
Idiomatic chord progression writing in most western music is not necessarily cyclical and linear, however. Instead, each harmonic verticality has multitudes of subsequent chords to progress to and through—depending on the syntax, form and grammar of the style, or even the individual voice of the composer. Progressions can therefore be thought of as graphs. To account for this syntactical and formal element of western music as well as for flexibility in future system development and composition, I programmed a HarmonicWeb object in Python to agnostically handle different models of harmonic progression in the equal-tempered system.
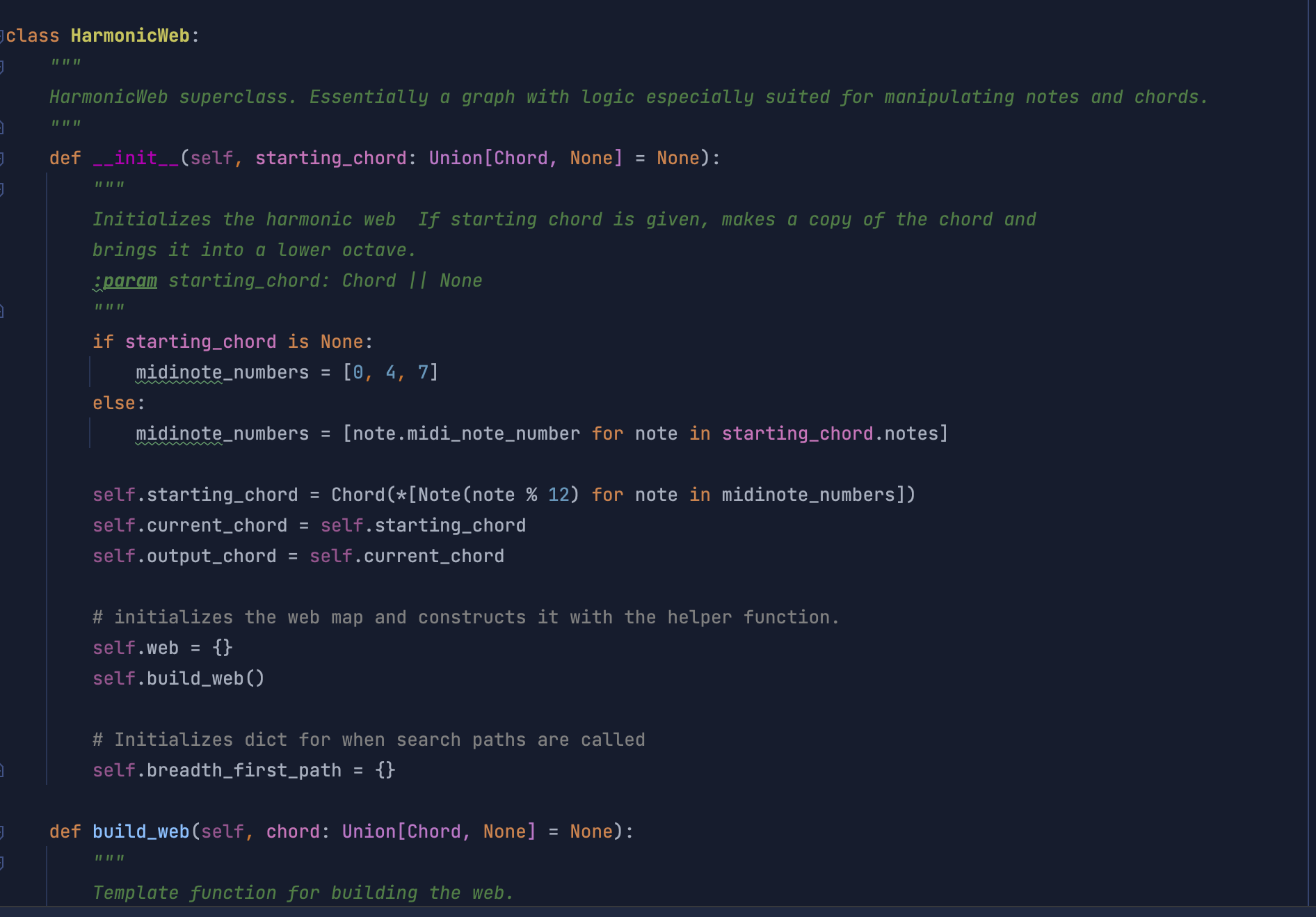
Using this representation of harmonic motion, I am able to randomly plot paths through the graph or search for harmonic destinations and build paths to them. An important feature of this object is that each chord can have a different number of chords to progress to. This functionality offers many options for generating variable pitch content over time. It also offers the compositional choice of generating more shocking or smoother aesthetic results when users submit texts and the system is iterating over a progression generated by the HarmonicWeb object.
Indeed, in much of the earlier design iterations, I deployed a version of the HarmonicWeb object that contained (algorithmically generated) data from a neo-Riemannian Tonnetz:
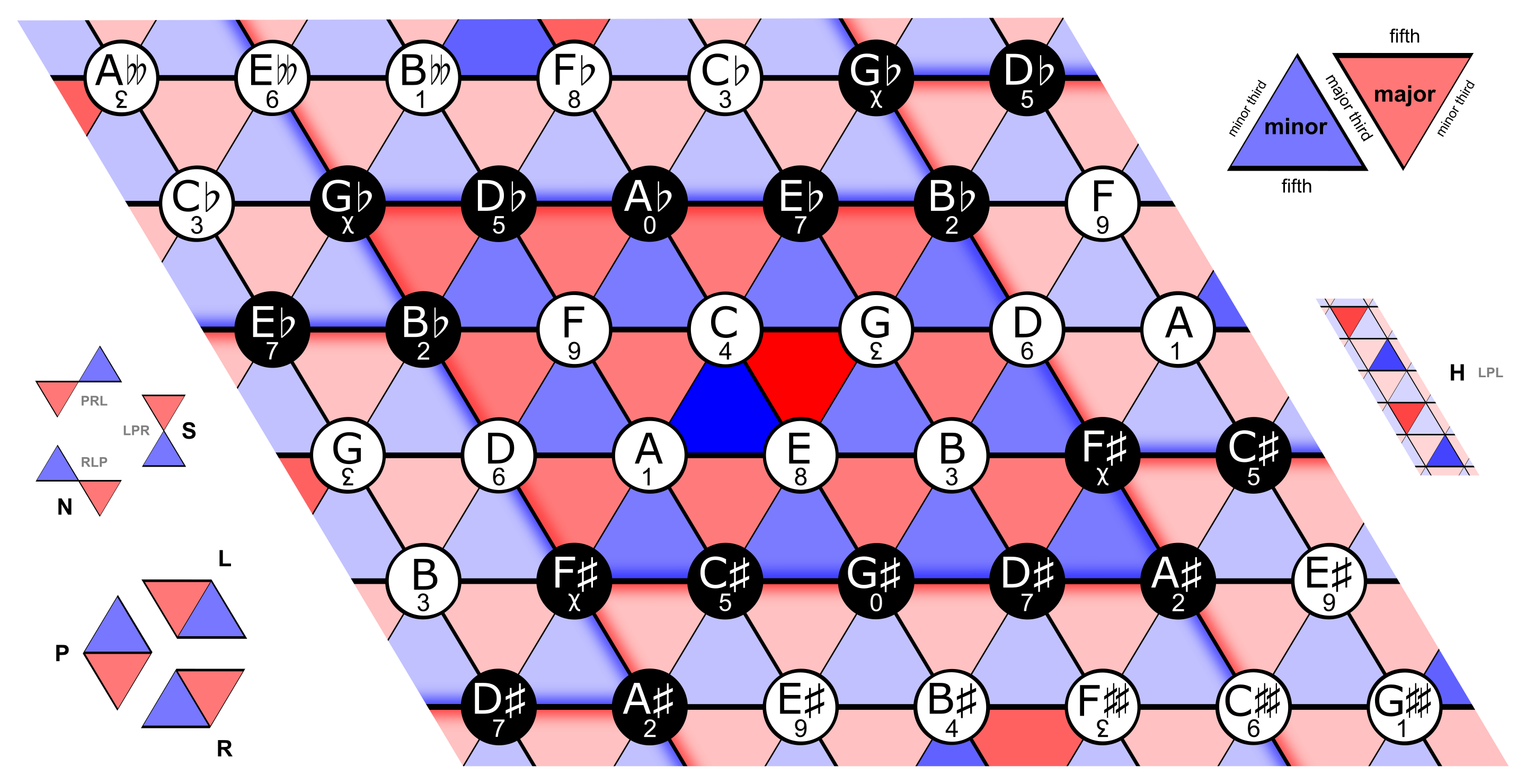
Alongside determining how the harmonic language of the work would be structured, I also mapped the semantic and linguistic features of submitted texts to the sound synthesis parameters and musical content.
Mapping Individual Texts to Sound
In Digital Discourse, each text generates its own musical gesture. The program realizes this by mining the text for its linguistic features, and by mapping them to parameters common in sound synthesis and music more generally. The linguistic features mined include average sentiment, parts of speech, length of text, and emojis used. The documentation of the code base further illustrates the functionality of the mappings. However, I have provided a table that describes these mappings:
| Sound Synthesis Data | Linguistic Data |
|---|---|
Total Duration of Musical Gesture | Length of Text |
Delay Time | Parts of Speech |
Delay Decay | Parts of Speech |
Reverb Predelay | Difference From Corpus Average Sentiment Data |
Reverb time | Difference From Corpus Average Sentiment Data |
Reverb Low Pass Filter | Difference From Corpus Average Sentiment Data |
Reverb-Input Mix | Difference From Corpus Average Sentiment Data |
Panning Control Duration | Length of Text |
Panning Start Point | Compound Sentiment Score (-1 to 1) |
Panning End Point | Key to Inverse Sign of Compound Sentiment Score (if sent['compound'] == 0.2, sent_key = 'neg') |
Phase Modulation Frequency | Number of Emojis |
Phase Modulation Amplitude | Average Sentiment of Emojis |
Octave Displacement | Length of Text |
No. Instruments Run | Hash of Sentiment Values |
Pitch Content & Randomization of Pitch Weighting | Sentiment Data |
Rhythmic Onsets | Number of Tokens |
Empty Rhythmic Values | No. Discrete Parts of Speech |
Some of the mappings here are simple, as is the case with the total duration of the musical gesture, where longer texts produce musical gestures that are longer in duration. Some are rather complicated, however, as is the case with the pitch content and rhythmic content generators.
For example. As already mentioned above, pitch content is drawn from the broader HarmonicWeb object that represents the possibilities for chordal progression. The question becomes, then, which notes for each harmonic verticality would be selected.
As the table above shows, I used sentiment data to determine pitch content and selection weighting. To add some variability to the harmonic language, pitches in Digital Discourse could be selected not only from the current chord selected in the HarmonicWeb object, but also all of its neighbor chords. The sentiment data for each text that I received from NLTK’s VADER, however, only gave me four values:
| Sentiment Type | Range |
|---|---|
| Negative Sentiment | 0.0 <= n <= 1.0 |
| Neutral Sentiment | 0.0 <= n <= 1.0 |
| Positive Sentiment | 0.0 <= n <= 1.0 |
| Compound Sentiment | -1.0 <= n <= 1.0 |
As a method of mapping this sentiment data to weights for acquiring pitch content from the current chord and its neighbors, I decided to use trigonometry to aggregate the sentiment data. I laid out the following ground rules:
- The current chord is represented by the center point of a circle whose radius = 1.
- All of its neighbor chords are represented by points on the circumference of the circle equidistant from one another. For example, if the current chord has eight neighbor chords that it could be followed by in the HarmonicWeb object, these chords are represented by the vertices of an octagon inscribed in the circle.
As a hypothetical example, the data in the HarmonicWeb object is represented by the current chord as a key, and a list of subsequent chords as the value.
{C-Major: [G7, a-sus4, Db6, Db7, F9, Bb-Maj, AmM7, dmm7]}This {key, value} pair relationship can be visualized as follows:
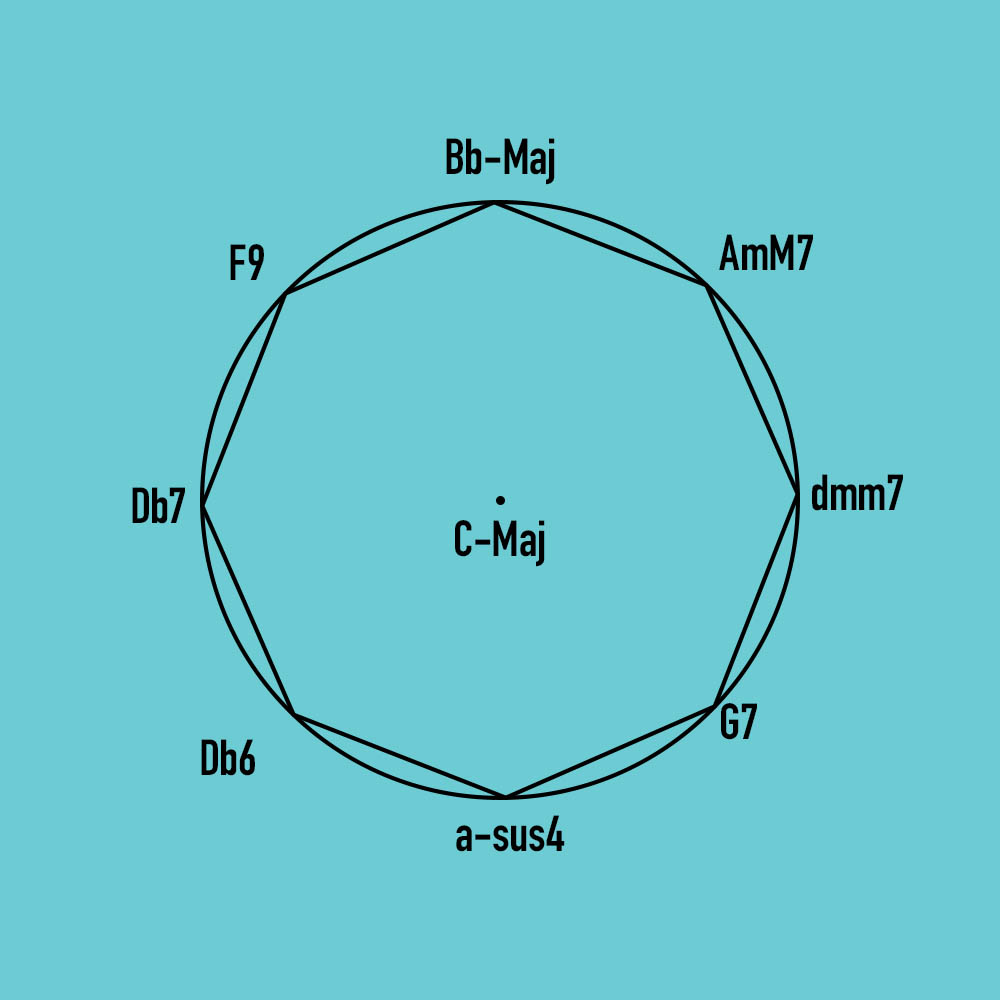
- The average negative, neutral, and positive sentiment values are mapped onto one of three radial line segments, whose angles are equidistant from one another. These values then become points in two-dimensional space using trigonometry.
For example, if the average sentiment dictionary of a text is: {‘neg’: 0.0, ‘neu’: 0.25, ‘pos’: 0.9}, the points are mapped on the sentiment line-segments as follows:
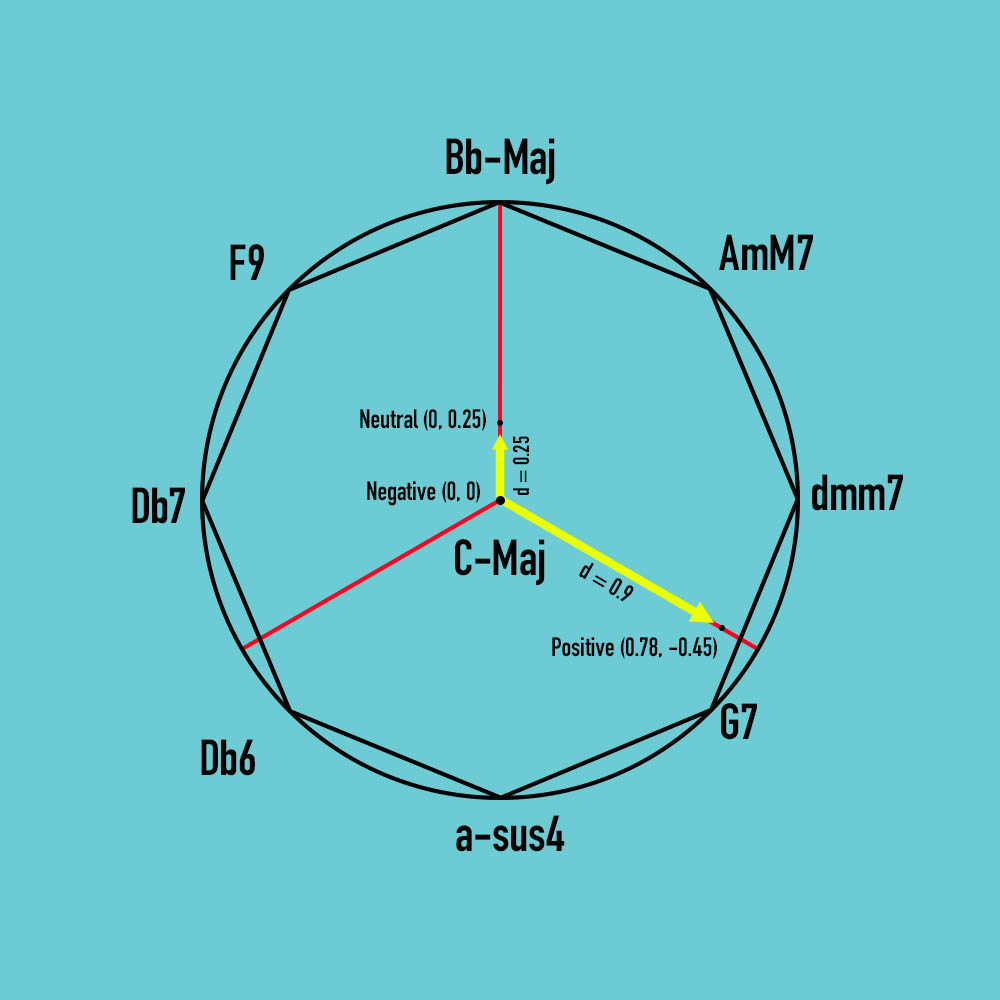
- All three points are then added via Cartesian addition to produce a new point.
In this case, it uses the following: (0.78, -0.45) + (0.0, 0.25) + (0.0, 0.0) = (0.78, -0.2)
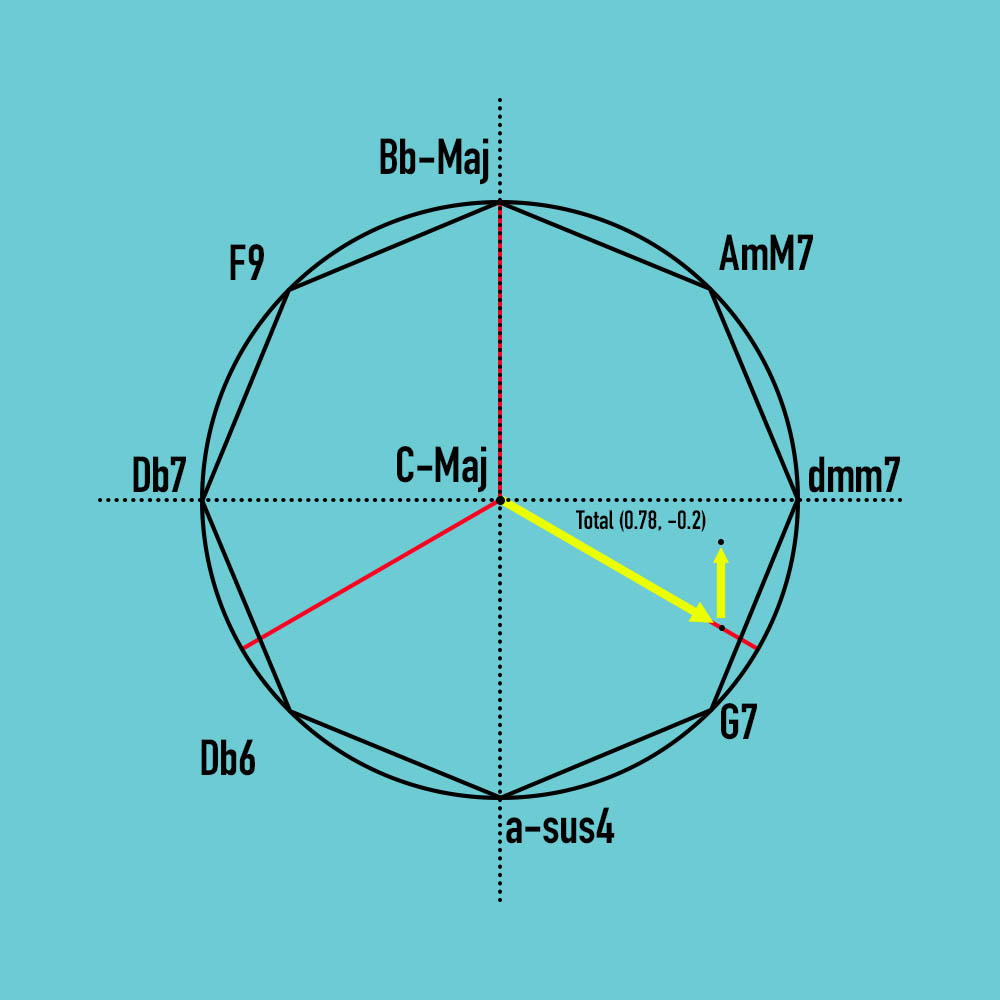
- This new, summed point falls on a triangle that is defined by two of the inscribed octagon’s vertices and the center point of the circle. In this example, the triangle is thus defined by the points with chords C-Maj, dmm7, and G7.
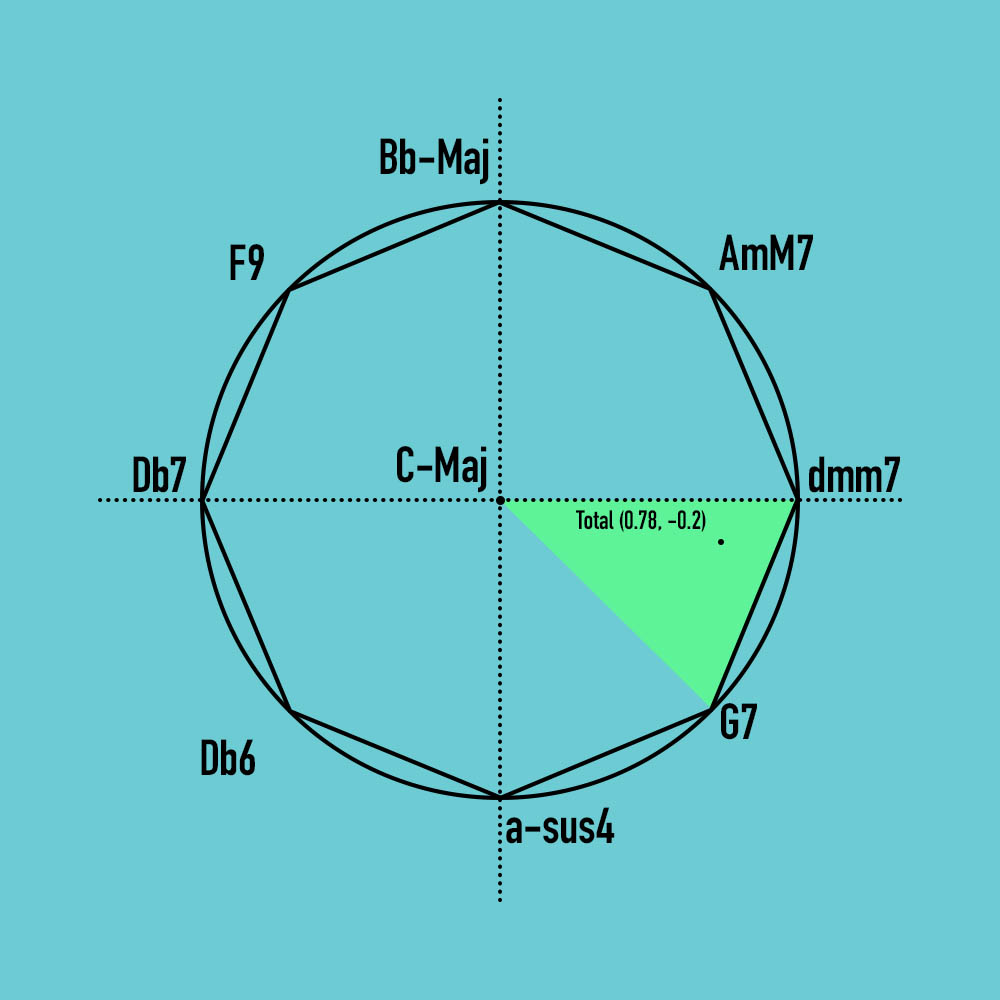
- The distance of this summed point from each of the respective vertices of the triangle then becomes the weighted probability with which notes are selected from each of the vertices’ chords:
def get_distance_between_points(point1: tuple, point2: tuple):
"""
Calculates the distance between two points on a cartesian plane.
:param point1: Tuple (x, y)
:param point2: Tuple (x, y)
:return: Float as distance
"""
return math.hypot(point2[0]-point1[0], point2[1]-point1[1])
def get_point_end_vertices_distance(point: tuple, vertices: list):
"""
Gets the distance between a point and a list of points.
:param point: Tuple (x, y)
:param vertices: List of tuples e.g. [(x, y), (x, y)]
:return: List of floats.
"""
return [get_distance_between_points(point, i) for i in vertices]
def get_linear_weights_by_distances(point: tuple, *vertices: list):
"""
Gets the weights of the distances between a point and a list of vertices. If distance between point i and vertex j
is 0, weight = 1.
:param point: tuple (x, y)
:param vertices: List of tuples [(x, y), (x, y)]
:return: List of floats.
"""
distances = get_point_end_vertices_distance(point, *vertices)
return [(sum(distances) - distance) / sum(distances) for distance in distances]In this example, the distance from the added sentiment point to the dmm7 vertex is approximately 0.273.
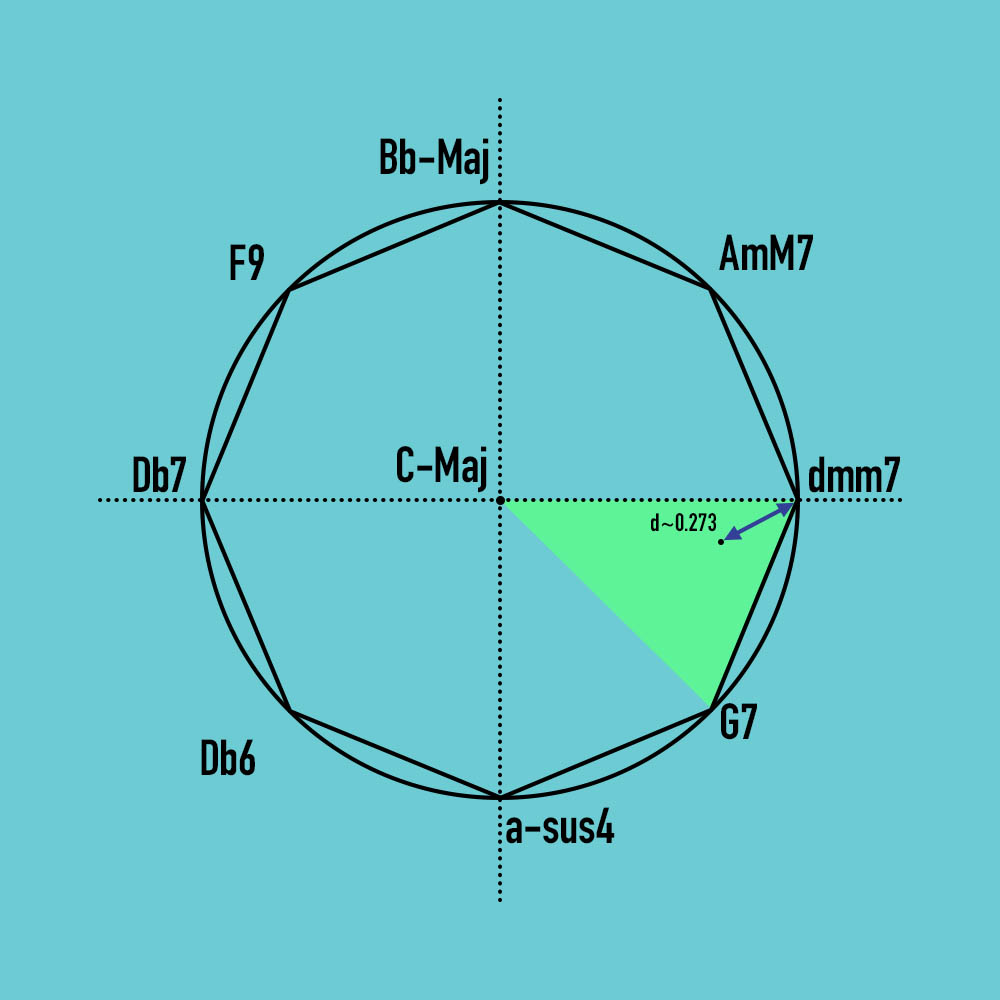
In the algorithm, the probability weights are not determined by (1 - distance) / 1. Instead, they are determined by the following equation:
(sum(distances) - sent_vert_distance) / sum(distances)This leads to higher proportional probabilities that notes will be ‘borrowed’ from each chord. It also leads to a harmonic locus for each submitted text that is a bit richer than the lower probabilities that would be derived from (1 – distance) / 1. In the example above, the resulting weights are:
dmm7: 0.8219802230501223,
C-Maj: 0.517870591351329,
G7: 0.6601491855985487Musically, the algorithm provides aesthetically interesting and formally coherent results a few reasons, as the average sentiment value of a text that is derived from VADER tends to result in points that clump in particular areas of the Cartesian plane. For one, audience members tend to submit texts with neutral or positive sentiments. Further the average sentiment value usually only emphasizes one value, i.e. positive (and maybe neutral), but not negative. Finally, the sentiment of texts submitted also tend not to be very strong, with the ‘added sentiment point’ of any given text being not too far from the origin, and thus emphasizing the home chord.
Just as a final note, the visualization I have provided here is an approximation of the algorithm for ease of understanding. The main difference between the graphics here and the algorithm’s inner workings is that the angles of departure for the sentiment value rays are different than 90º, 210º, 330º (and instead are really 0º, 120º, 240º).
The real benefit of this algorithm is that submitted texts with similar sentiments will draw on similar harmonic content. Points that are close together will fall on the same triangular sub-plane of the inscribed shape and also generate similar proportional weightings.
Scored Version
Performed by the Peabody Laptop Ensemble on March 14th, 2022.
Performers: Julio Quinones, Carson Atlas, Eugene Han, Harrison Rosenblum, Yi Zhou, H. Lin, Wenyun Liu, Devorah Berlin, Angela Ortiz, & Michael Milis
See above for the score and its documentation.
Cybernetic Republic
Live Version
Performed at Stony Brook University and Online, April 19th, 2022
Examples of generative Algorithms
Chord Progressions: Distributing Harmonic Motion Across Metrical Structures by Recursion
In much of western music, harmonic content develops over durational and/or metrical strata. In Cybernetic Republic, I deploy a simple model of harmonic rhythm that distributes chords across metrical sub-units as equally as possible (with constraints). The algorithm achieves this through recursion and in a manner agnostic to the number of beats in a meter. In principle, there are three cases to consider when distributing the chords:
- When the number of chords is less than the number of measures at the phrasal level
- When the number of chords is equal to the number of measures at the phrasal level
- When the number of chords is greater than the number of measures at the phrasal level
Case 1:
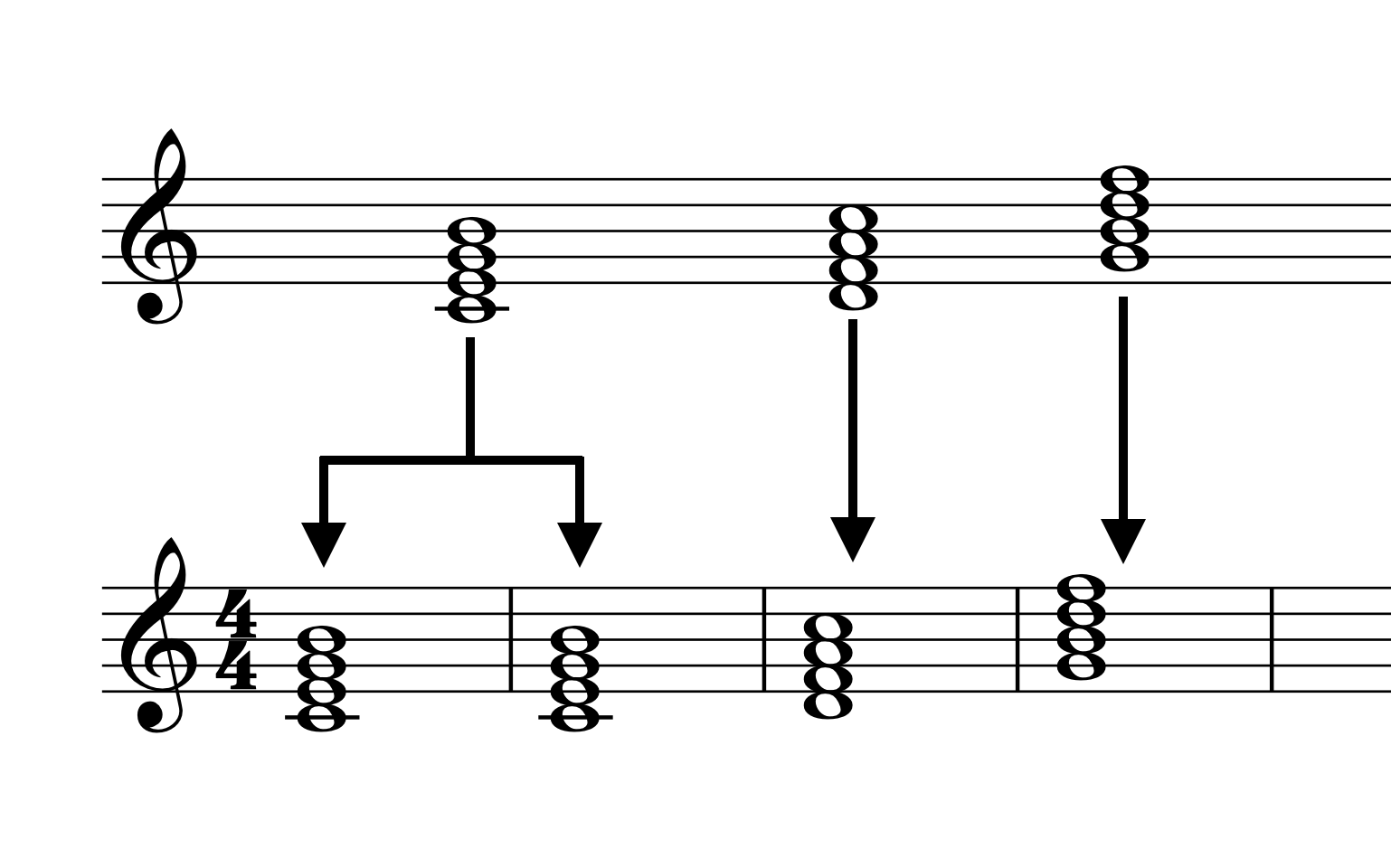
When the number of chords is less than the number of measures at the phrasal level, the algorithm iterates through the chords in a given chord progression array, starting with the first chord, and adds another of the given chord until the number of chords equals the number of measures.
Case 1, Figure 1:
Case 2:
When the number of chords is equal to the number of measures at the phrasal level, the chords are mapped to each respective measure.
Case 3:
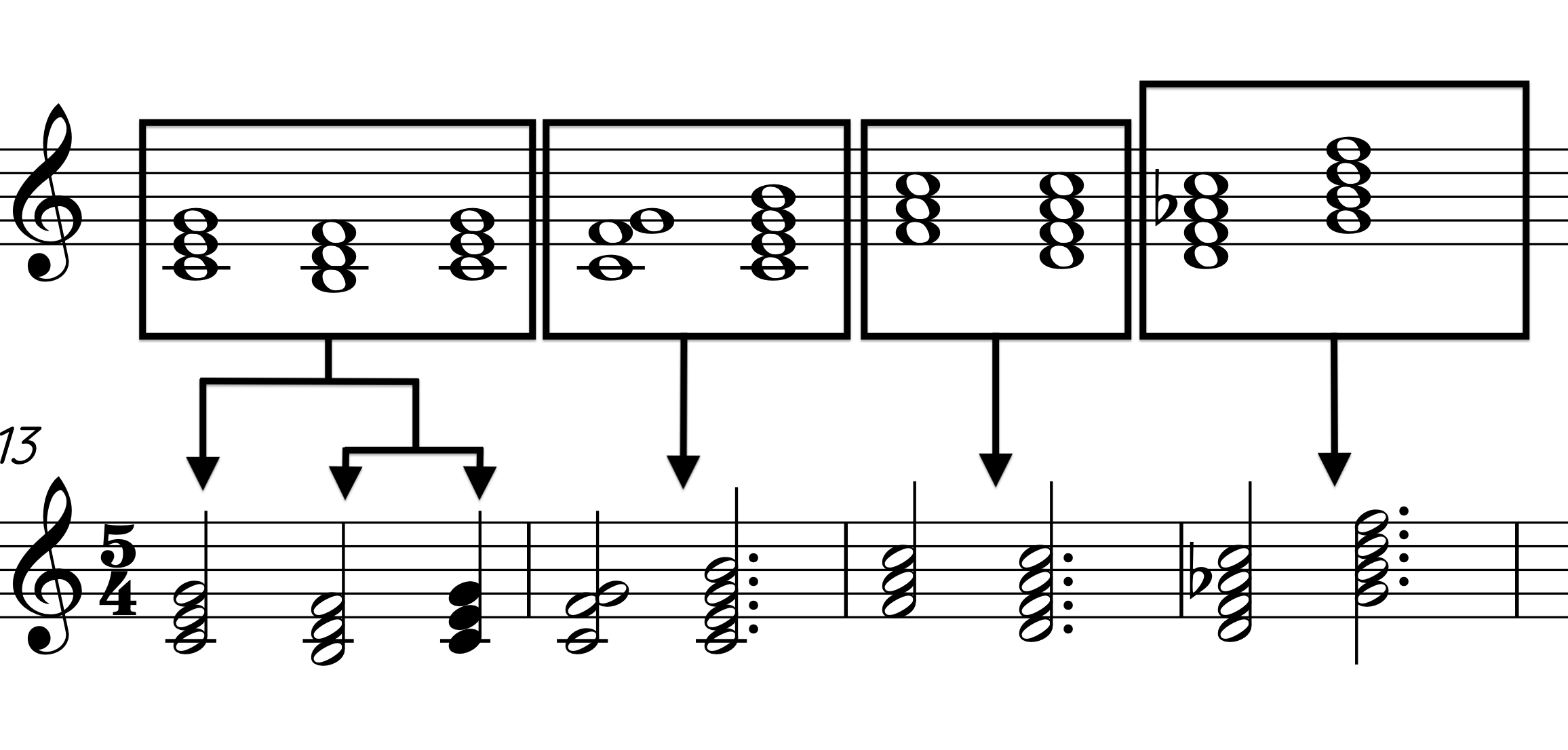
When the number of chords is greater than the number of measures at the phrasal level, the chords are recursively distributed amongst the beats of each measure, starting first with the primary subdivisions of each measure, and then continuing on down to the quarter note level by order of measures. The algorithm currently does not accept subdivisions smaller than a quarter note to limit freneticism in an already up-tempo, beat-based style of music.
Case 3, Figure 1: 6 Chords in a 4-measure phrase with a asymmetrical meter of 5, subdivided as 3+2:
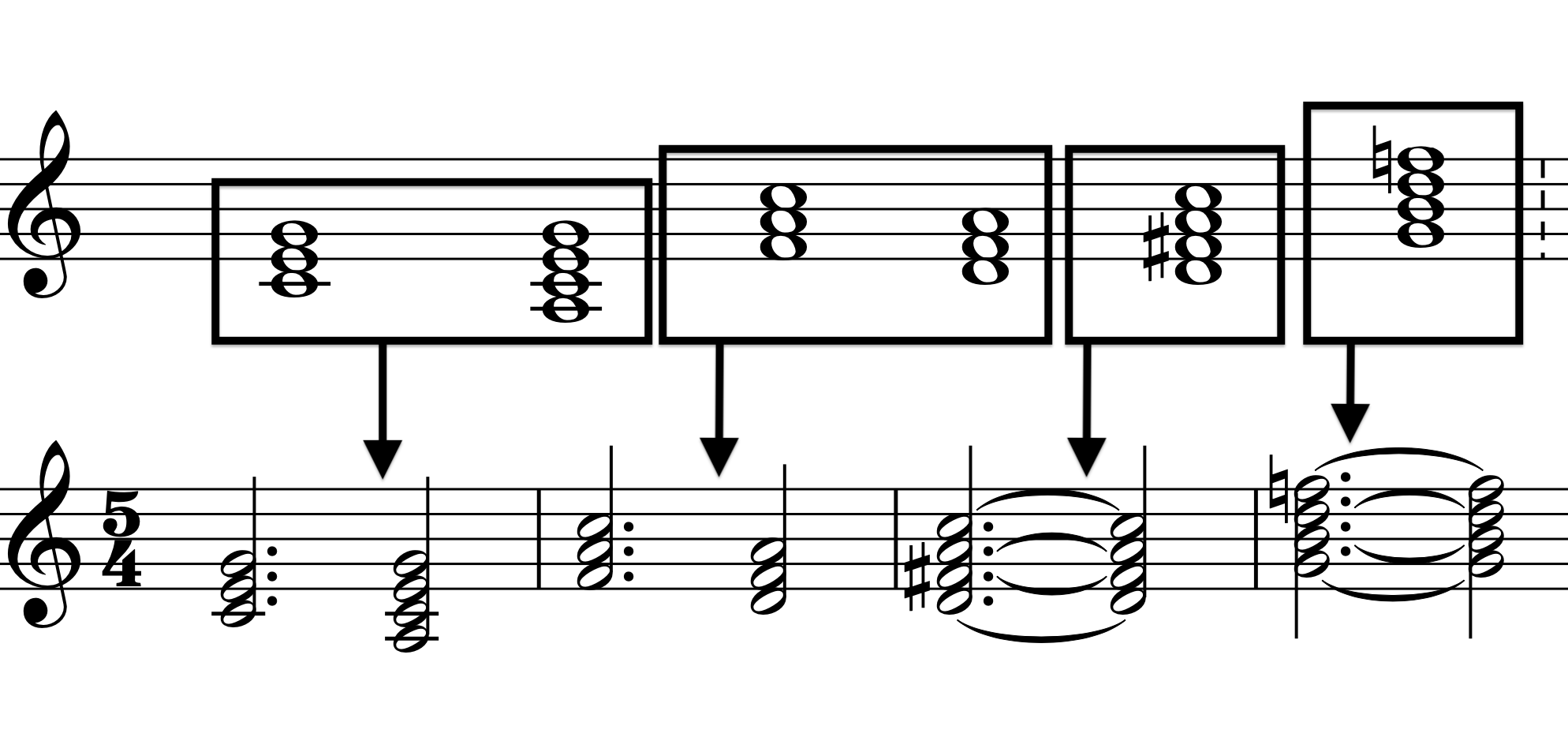
Case 3, Figure 2: 9 Chords in a 4-measure phrase with an asymmetrical meter of 5, subdivided as 2+3:
Walking Bass Line: A Simpl(e)-ified Algorithm
This algorithm builds a walking bass line by tracing notes step-wise between the bass notes of each chord in a measure. The bass line walks either by chromatic or scalar step. On the anacrusis to the next chord (wherever that may fall in a four-bar phrase), the algorithm may add in various tonicizations and extra rhythmic values to imitate improvisational playing. The bass line gains different idiomatic options based on whether the line is ascending or descending. For example, when the bass line is walking down the input scale (rather than chromatically), the line can step chromatically down through the ultimate scale degree before arriving at the down beat of the next chord in the harmonic rhythm.

In walking bass lines (very generally, and very loosely stated here!), a chromatic upper neighbor on the anacrusis is not as idiomatic to ascending lines, and as such is disallowed in the function calls. For more information on this algorithm, please see the code documentation.

Rhythm Sections and Metrical Conformation via Array Slicing
The identity of the percussion or rhythm section tends to be strongly identifiable in beat-based music-making. Further, idiomatic performance or creation of particular kinds of music are often marked by normative metrical and rhythmic patterns (e.g. the strong identity that the dembow pattern gives to Reggaeton). These metrical and rhythmic patterns mingle with the timbral identity of the instruments used (e.g. the long-standing use of 808 sounds in trap and other sub-genres of hip-hop, or the prevalence of drum kit in jazz).
When trying to create musical results that the audience recognizes as corresponding to vote options, challenges can overlap and compound. On the one hand, audience members should be able to connect textual relationships with the system’s musical output. On the other, because the system provides the option to vote on both meter and rhythm section identity, programming an aesthetically recognizable result for audience members based on a mix of these two vote layers is difficult. The identity for both meter and the described rhythm section should be recognizable regardless of the merging of meters with rhythm sections that would normatively be typified by another metrical pattern. For example, in Politics I’s Cybernetic Republic, the audience can convert a rhythmic pattern played on sampled kit that is inspired by Dave Brubeck’s take-five (originally in five) into meters of four, nine, etc.
Example Take Five from Five to Nine:
Below is an example of the Brubeck-inspired rhythm pattern. It transforms the originally composed asymmetrical five into a compound nine meter. I have added in sounds that help listeners track the meter and its change. The claps indicate the primary beats of each measure (three-plus-two in the original and three-plus-three-plus-three in the newly conformed meter). A crash and a bass drum hit with significant reverb indicate the moment the meter changes. The meter changes on the downbeat of bar lines via pattern quantization in SuperCollider.
Without help from the mixed in claps, crash, and kick, the composition sounds as follows:
The conformation algorithm comes from a type of rhythm generation automation called breakbeat cutting or slicing. Because metrical information can not only be seen and heard as sonic data and experiences, but also as arrays filled with note onsets, durations, and rests, rhythm pattern sub-units can be type-tagged and stochastically shifted around to beats with similar accents or metrical roles to provide variation. In the case of Politics I, the slicing is conducted deterministically rather than algorithmically. In other words, for this iteration of Politics I, I have chosen how to slice Take Five into Take Nine. This is a point for future development however (see future development).
Example of Values Generated from Original Data Set by TakeFive Class in Python:
Kick array in 5. Items prepended with ‘/r’ indicate rests.
[0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25']Kick array in 9. Note that this array is shorter because I chose for the breakbeat slicing to result in half the number of measures total.
[0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25', 0.25, '/r0.25', '/r0.25', '/r0.25', '/r0.25', '/r0.25']Melodic Generation and Maximizing Ornamentation
Ornamentation is another domain of music in the western concert art music tradition that is highly algorithmic. In Cybernetic Republic, I looked towards some of the most basic and frequent ornamentations in the classical canon for generative functions to implement. This included appoggiaturas, suspensions, mordents, turns, and trills.
Mordents’ (upper or lower) rules, for example, are fairly simple: two short notes followed by a longer note, with the first and third note in the gesture being an indicated structural note. In much composed and improvised music, this structural note could be a non-chord tone. In Cybernetic Republic, however, the structural note is always a chord tone. The second note in the group is a chromatic or scalar upper or lower neighbor.
Example of Mordents Possible in Cybernetic Republic:


In Cybernetic Republic, the resolution tone of mordents can be sustained for a short or long period of time.
One of the melody generators in Cybernetic Republic maximizes ornamentation—which can be comical for the maximal aesthetics of its baroque-ness, but it also interesting to listen to.
Example of result from MaximumOrnamentation melody generator:
Technoautocracy
Live Version
Performed at Stony Brook University and Online, March 1st, 2022
Simulation Where Audience Wins
In this simulation, the audience wins. The audience generally wins if audience members have reduced the so-called ‘anti-human instrument’s’ life bar down to zero. Attacks on the machine play back a selected chord from The Impossible Will Take A Little While’s ‘No Future Without Forgiveness’—a prior work of mine the draws inspiration from a text by Desmond Tutu. The broader message of The Impossible Will Take a Little While is that social change and progress are led by legions of unsung people and political acts over a sustained period of time. These ‘attacks’ precipitate responses from the system that are loud and aggressive, and are created through the granulation of a recorded buffer. When the audience wins, the screen fades to white, and quick repetitions of the chords from ‘No Future’ are played back until the end of the piece.
Simulation Where Audience Loses
In this simulation, the audience loses. The audience loses if either:
- Enough audience members supported the machine with the sentiment that they expressed in their submitted texts
- The audience was unable to counteract the healing of the machine’s health bar.
At the end of the movement, the visuals fade to black and the sine tones homogenize into a piercing scream.
There are two ethical points communicated through Technoautocracy:
- All autocratic forms of government must wage violence upon their subjects to maintain their power order and the status of their ideology.
- Even violent, autocratic forms of governance can be utopian in their ideology—hence the use of a homogeneous, ascending sine tone as the result of subjective diversity being lost. Utopia under a singularistic ideology will only be achieved once there is a unitary subject.
Process and Development
Digital Discourse
SuperCollider vs. Ableton Live
When I began developing Politics I, my original plan was to develop all synthesizers and effects myself in SuperCollider. Achieving this goal, however, proved very code-heavy, and it left me debugging synths and having to work hard to store and control them in memory rather than spending time addressing the theoretical and aesthetic goals I had for the piece. After coding up a working version of Digital Discourse in SuperCollider, my advisor, Meg Schedel, suggested that I send data over to SuperCollider and then, instead of using SuperCollider’s synthesis engine, sclang, for sound synthesis, send MIDI information from the sequencer out to a DAW. It took me about a day to get the pattern scheduler refactored and sending relevant data out to Ableton’s Live. Ultimately, not having to create my own synthesizers and control the digital signal processing (DSP) chains in Politics I was a definitive advantage to the work process. I could focus more on the political and musical theory and the piece’s aesthetics rather than troubleshooting the technical background.
Still, there were some positive aspects to generating sound with SuperCollider. In this early version, testing the digestion of tweets from a stream as the harmonic content walks around a neo-Riemannian web, the chirping and droning from SuperCollider is quite satisfying.
For the first live performance of Digital Discourse (see above), the work used SuperCollider. Live proved to provide a greater variety of sounds, along with less debugging and the tactility and familiarity of using a DAW was also a plus. In the example below, I am feeding various data that is meant to exploit the text-mining features of Digital Discourse’s algorithm. Note that in this example, the visuals are near their current state, with only the helpful and colorful text boxes still to be implemented.
Visuals
Originally the visuals of Digital Discourse had text fit into equally sized boxes, and these boxes would float up the screen. The left side of the screen featured a QR code, the SMS number, and the Twitter handle so that users could get connected to the work.
While this iteration was arguably visually more compelling than the program’s current state, there were several user experience problems with this implementation. First, the information for getting users online took up a third of the screen space. Second, users’ texts tended to come in clumps, as people would tweet/text, wait to see their message, and then return to typing. The clumped texts would overlap, making many unreadable. The submission clumping, when combined with the visual clumping, also made it hard to know whose tweet/text created which sound. Finally, when someone wrote particularly long texts, my algorithm would reduce the font size to fit it into the equal-sized, floating text boxes, which made the texts illegible.
As a consequence, I ultimately decided on a chatroom style for organizing texts. With this design choice, text boxes can vary in height and the static font size can be set to be large enough for legibility. Further, one text now appears clearly associated with one sound, with no visual overlapping.
Technical Challenges
Beyond the technical challenges of displaying texts in a manner legible to both sight and its co-appearance with sound, there are a number of visual challenges that I believe still need to be addressed. First and foremost, I am not a visual artist or UI designer. Consequently, my technical capabilities on this front are naturally weaker than I would like, which played out in the creative process across all the movements of the work. Beyond this, there are some concrete items that I believe were particularly challenging across all technical domains (whether musical, systematic, or visual):
- The system not only digests tweets/texts and generates sound based on the features of the text, but it also walks through the HarmonicWeb object over a period of time. This required me to dive into problems associated with multi-processing and multi-threading, whether it be shredding objects in memory or passing objects safely between processors and threads.
- This particular movement relies heavily on natural language processing techniques—a research task far outside my earlier, comfortable domain of music composition. What features should be mined for? How should I compare texts using the various models and computational linguistic research out there? These are but a few examples of the questions I had to understand and efficiently address.
- It is a significant aesthetic challenge to generate sonic information from texts that represent the features of the textual information while also doing so in a replicable and engaging way.
Future Development
Looking forward, I have identified a few key items that will improve the system:
- It is possible to build out a machine learning algorithm based on texts stored in the Politics I, Digital Discourse database. After enough performances have been run, and enough documents (tweets/texts) have been stored from the audience, I can create a Latent Semantic Analysis (LSA) space of the kinds of texts and tweets people tend to submit. Where tweets/texts fall within this space can then be a parameter for further sound synthesis.
- Incoming texts should be related to other, already submitted texts while they are being digested (and not when the average corpus values are being generated after 30 seconds have passed). I believe it would greatly reify text-to-sound relationships if I was able to use this data to select the synthesizer MIDI channel. Then, similar texts would trigger the same synthesizer(s) and the timbral space of the music would reflect the semantic space of text. This can be achieved though LSA mapping, or alternatively, much in the style of TweetDreams, relating texts via cosine similarity and building out a tree-node structure, with child nodes inheriting parent node synth channels.
- The HarmonicWeb object is currently highly under-utilized. Making use of its full power is also an opportunity for deploying machine learning in order to develop Markov-chain probabilistic weighting on corpuses of composers’ works, or even my own harmonic language.
Cybernetic Republic
Live, Max for Live & Reinventing the Wheel
After developing Digital Discourse to use the power of Live, one challenge was gracefully controlling sound synthesis parameters that change gradually over time, much like turning the knob on the pan button. In Digital Discourse, I had written functions that expressly controlled MIDI continuous control (cc) parameters. See for example the following code for controlling panning:
~controlPan = {
// #################################################################################################################
// ~controlPan
// -----------------------------------------------------------------------------------------------------------------
// Mimicking a Line function in Max or Supercollider, this function spins off a routine when triggered to control
// the MIDI values of an instrument's pan over a given time span.
// #################################################################################################################
arg midiOut, channel, startVal, endVal, time;
var routine, increment, distance, waitTime, currentVal;
distance = abs(endVal.linlin(-1, 1, 0, 127) - startVal.linlin(-1, 1, 0, 127));
waitTime = time / distance;
currentVal = startVal.linlin(-1, 1, 0, 127);
if(startVal >= endVal, {
increment = -1;
}, {
increment = 1;
});
routine = Routine.new({
if (increment > 0, {
forBy(currentVal, endVal.linlin(-1, 1, 0, 127), increment, {
currentVal = currentVal + increment;
if(currentVal > 127, {currentVal = 127});
midiOut.control(0, channel, currentVal);
waitTime.wait;
});
}, {
forBy(currentVal, endVal.linlin(-1, 1, 0, 127), increment, {
currentVal = currentVal + increment;
if(currentVal < 0, {currentVal = 0});
midiOut.control(0, channel, currentVal);
waitTime.wait;
});
});
});
routine;
};In Cybernetic Republic, this was not necessary, as most of the heavy lifting was being done by the generators and algorithms that defined textural layers like melody, bass, harmonic rhythm, etc. Still, for sonic variability it is better to have some of these commonly continuously controlled parameters (like filters, panning, velocity, overall levels, aux sends) change over time—even if randomly.
Max for Live proved to be a fairly strong solution out of the box, and the smoothed randomization mappings added sonic depth to the generated, textural layers.
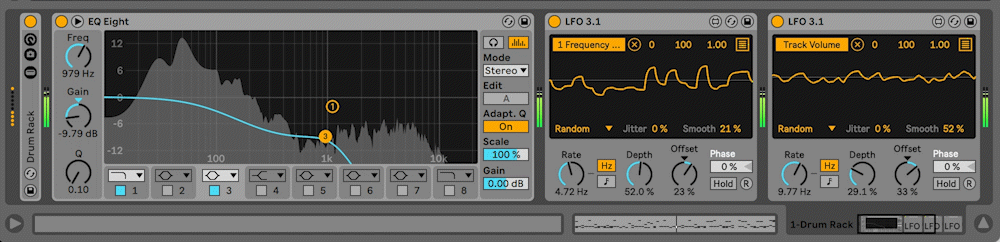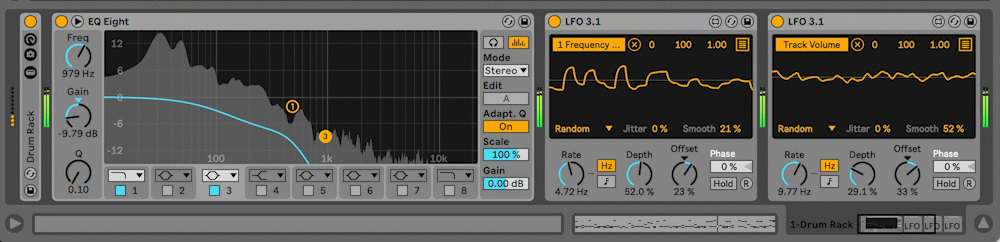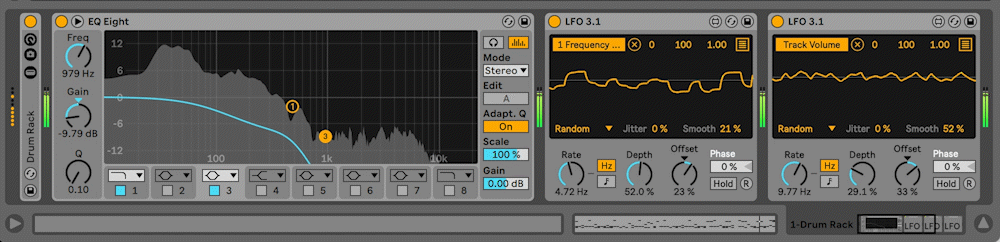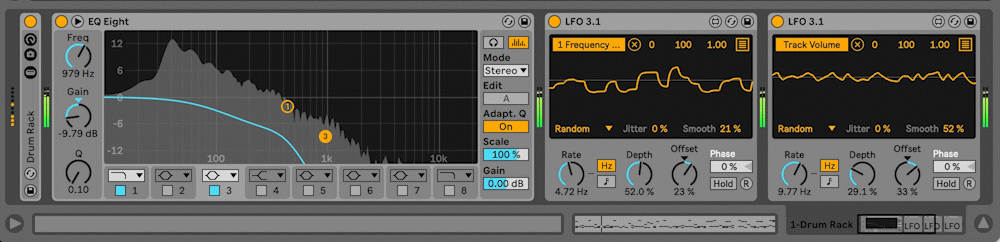
Visuals
The visuals for Cybernetic Republic are kept simple. Vote options scroll across the screen from right to left, with constantly updating percentages falling to the right of the vote options. Development of these graphics was straight forward except for a technical issue that I believe is similar to one I encountered in Digital Discourse having to do with queuing and garbage collection but that I have not been able to debug yet. The background visuals are four different instances of Brownian motion constrained to the boundaries of the visuals window. The differently colored lines represent the various sequencing patterns running in SuperCollider: Rhythm Section, Bass, Middle Voices and Melody. The sequencing patterns send OSC to Processing and instruct the Brownian motion to advance one step in its life-cycle. In this way, the visuals are concretely connected to the musical materials, while still being unobtrusive enough to have vote options and percentages appear clearly.

Technical Challenges
There were a few technical challenges to address in Cybernetic Republic that are similar to those encountered in Digital Discourse. For example, Cybernetic Republic also required me to understand thread-safe memory handling and cross-domain communication. However, some of the largest technical challenges came from grappling with the abstract musical rules and the recursive interactions of said rules.
For example, before programming a Melody generation class, I needed classes of objects for containing musical data, such as Notes, Chords, Meters, Progressions, and Harmonic Rhythms, etc. This also meant that design choices made early on impacted the capabilities of the code I wrote to produce higher-order and more surface-level textural materials (like a melody). The goal thus became to write code that was as idiomatic to the forms, features, and processes of western, tonal idioms as possible without relying on the far-superior neural network I was born with and hard-coding (composing) too much data.
class Note:
"""
A simple note class with logic for printing self, object equivalence and comparison. Also, logic for transposition.
"""
def __init__(self, midi_note_number: int):
"""
Initialization for Note class
:param midi_note_number: int
"""
self.midi_note_number = midi_note_number
def __str__(self):
"""
Prints notes prettily based on the midi note number
:return: str
"""
NOTES_FLAT = ['C', 'Db', 'D', 'Eb', 'E', 'F', 'Gb', 'G', 'Ab', 'A', 'Bb', 'B']
NOTES_SHARP = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
octave = self.midi_note_number // 12 - 1
note_index = self.midi_note_number % 12
pretty_midi = "{flat}-{octave} or {sharp}-{octave}".format(
flat=NOTES_FLAT[note_index],
octave=octave,
sharp=NOTES_SHARP[note_index]
)
return pretty_midi
def __repr__(self):
"""
Representation of a note.
:return: str
"""
return '<{0}.{1} object at {2} || {3}>'.format(
type(self).__module__, type(self).__qualname__, hex(id(self)), self.__str__())
def __eq__(self, other):
"""
Tests numerical equivalence of the midi note numbers. Useful for testing whether two notes are the same
note. But not the same object.
:param other: Note
:return: Boolean
"""
if isinstance(other, Note):
return self.midi_note_number == other.midi_note_number
elif isinstance(other, int):
return self.midi_note_number == other
else:
return NotImplemented
...
AND SO ON AND SO FORTH! [You can read it all in the docs]
Future Development
As already mentioned, one of the greatest challenges while composing/coding this movement was thinking through the interaction, logic, and mechanisms of the musically generative classes. However, there are a few key areas that remain untested and some significant build-outs that could occur with the already written tool-sets in the future:
- Further melody, bass, middle voice and rhythm section subclasses would improve the variability and interest in the musical texture. At the same time, melody and bass lines probably have an abstracted superclass that logic can be deferred to (such as a MusicalLine class).
- Macro-structures were largely left out of the picture, but accretions of smaller musical sub-units into larger ones is already a domain for the program undergirding Cybernetic Republic. For example, in this movement meter subdivisions accrete into bars, and bars into 4-bar phrases. To be truly generative, larger formal structures would need to be addressed.
- Breakbeat cutting is a key area of musical generation in the RhythmSection class that could be much advanced with little effort. One option would be to type-tag different rhythmic sub-units. For example, kicks tend to be played on primary metrical subdivisions. In disco, the hi-hat is played on every eighth, and fills tend to operate as anacruses into new formalistic units. In this way, smaller, composed (or analyzed) gestures could be type-tagged, much like NLP software tags words by parts of speech. With these type-tags, probabilistic weightings could be given for a particular rhythmic gesture to fall on a metrical sub-unit, quite similar to the algorithm described by Nick Collins in “Algorithmic Composition Methods for Breakbeat Science”.
Technoautocracy
Audience Boss Fight
IIn Technoautocracy, the primary goal is to wage sonic violence upon the audience so that they react to the system. This can occur either by members of the audience leaving (and rupturing the consensus-based space of the concert experience) or by fighting the machine through the sending of texts with a negative sentiment. Part of this process of creation and encouragement was to develop sounds that are displeasing to most listeners.
For the most part, this meant using various noise producing unit generators (UGens) from SuperCollider, each of which has it own timbral profile. To increase the intensity and level of displeasure, Technoautocracy switches between several different noisy sounds, all while being underpinned by very loud, clipping, low-frequency noise. Finally, the music generator starts loud, and gets louder over time. Audience members must then bear the sonic violence to fight the machine, or hold their ears to protect themselves.
Most interestingly, people did seem to react negatively towards the sounds produced:
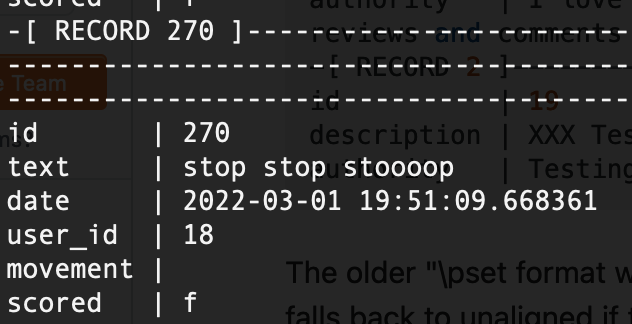
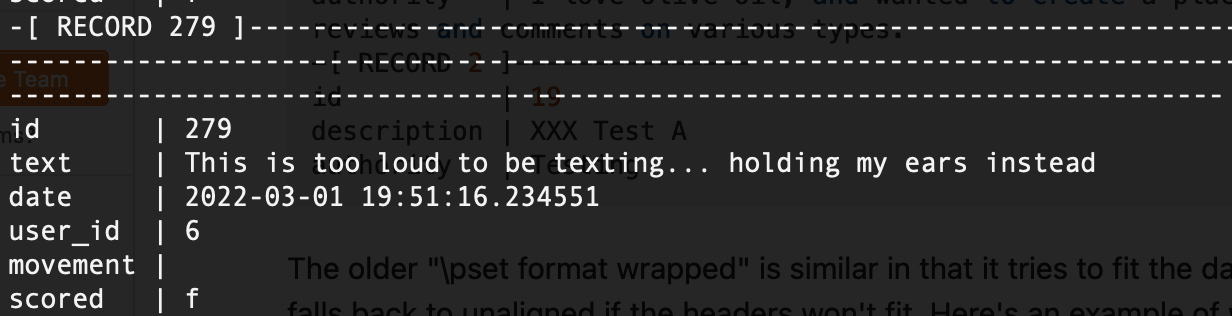
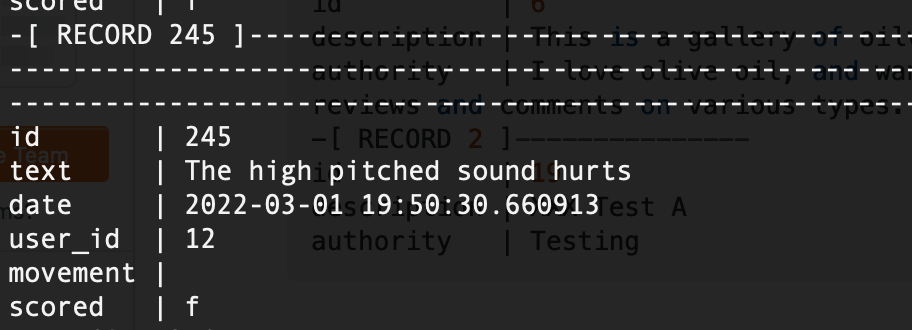
Others, meanwhile, appeared to enjoy it:
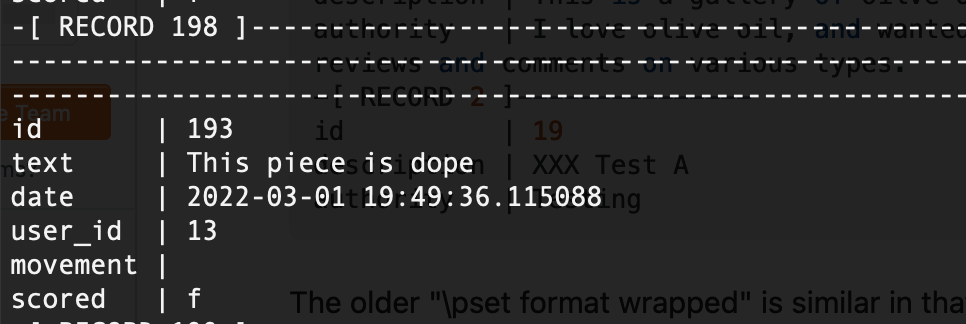
Visuals
I am most satisfied with the visuals in Technoautocracy. The visuals are comprised of many, small, glitch-based graphics I made out of a public domain image of a manufacturing robot that looks like a face.
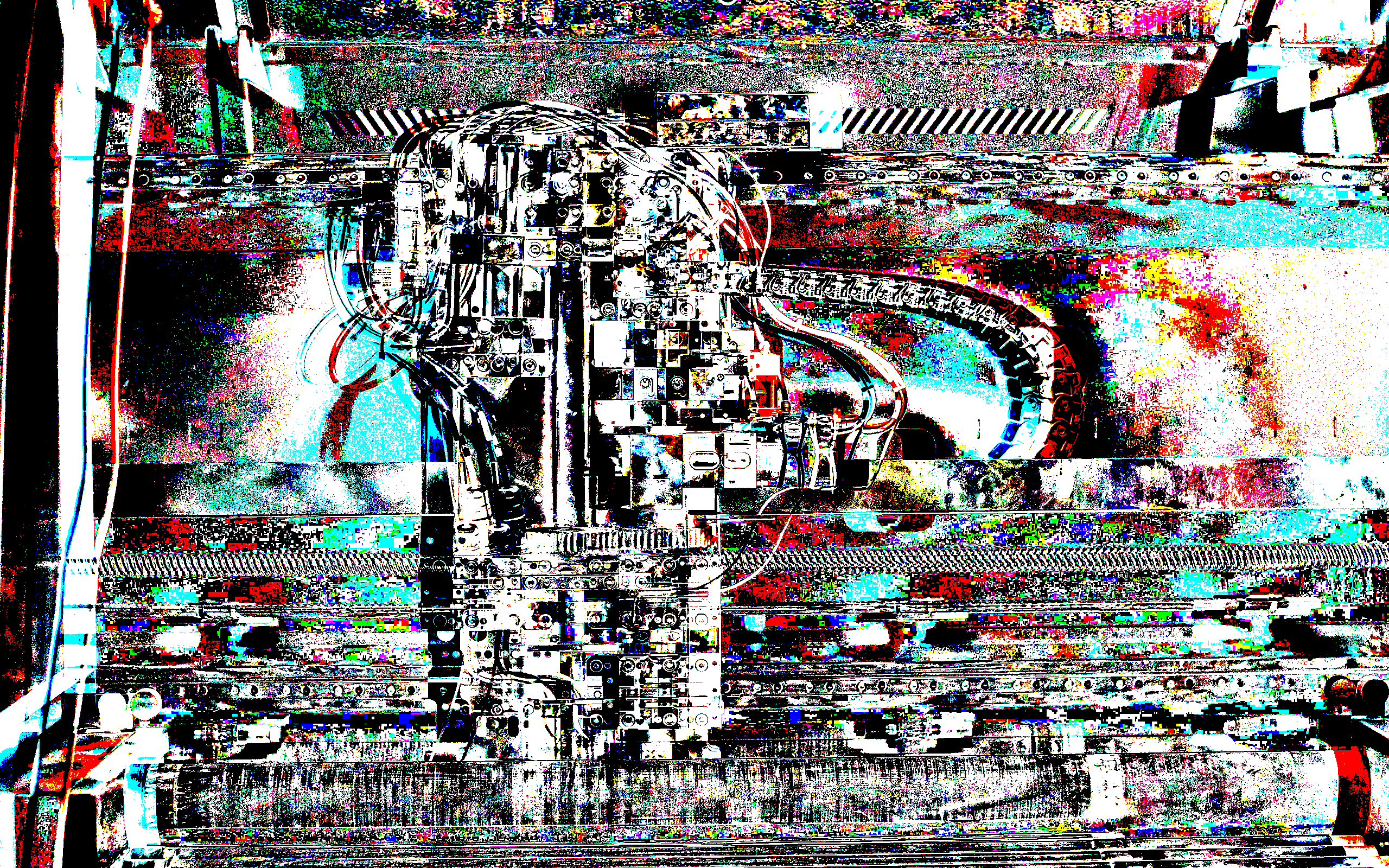

The visualization algorithm simply loads and renders a random image from the set after a random period. On the left of the screen floats a health bar that slowly fills or, if an audience member expresses a negative sentiment towards the machine, decreases. When a user attacks or supports the system, it displays their username, and the numerical amount by which they attacked or supported the system.
Technical Challenges
Technoautocracy posed far fewer technical challenges than the prior two movements. Essentially, all parts of the program are built around holding open communication protocols and updating values as message responses come in from the audience, all the while taking advantage of SuperCollider’s excellent and graceful thread handling through the scsynth server and sclang side routines.
There were design challenges, however. First, the name of the system seemed to prompt users to react against it in ways that are logical on further thought but I did not predict. In Technoautocracy, the system interprets audience submitted text only by performing sentiment analysis. Texts with a positive sentiment support the system, while texts with a negative sentiment attack the system. However, humans use language in ways that are far more complex than this domain of computational linguistic analysis implemented. For one, the piece’s title and the fact that it wages violence seemed to encourage the audience members to react against the machine by submitting texts conceptually antithetical to autocratic systems. Users submitted texts with words like ‘peace’, ‘resist’, and ‘democracy’, for example—words that are almost antonymic to violence and autocracy. However, when considering how submitted texts should interact with the system in the future, the salience that a word like ‘peace’ would have a positive sentiment score and trigger support for the system should not be simply disregarded. This is because the submitting user likely intended to disrupt the system.
Future Development
Despite the comparatively fewer technical challenges, there are few design choices that will help automate the variables that manage the stability and difficulty of fighting the machine:
- Because Technoautocracy is the final movement of the work, the system should be able to monitor the number of unique users and the level of activity by those users. Future iterations of Technoautocracy should deploy a weighting function that assigns values for the rate of the Technoautocracy’s healing, as well as its health reservoir.
- There are logic bugs, or communication issues in the SuperCollider code that can lead to the audience either winning or losing before (or after) the visuals have displayed the health bar reaching the minimum or maximum. Instead of handling this logic in SuperCollider, value dispatches should preferably come from Python, where messages are being received. This way, SuperCollider and Processing can receive commands for value updates at essentially the same time, rather than following the chronological sequence of Python->SuperCollider->Processing.
- As already mentioned, user submitted texts should have a predictable effect on the system, and their intentions should be considered. Therefore, the system’s NLP should take into account antonyms to ideas conceptually related to violence and autocracy. This can possibly be accounted for via Princeton’s WordNet.
Technical
Architecture
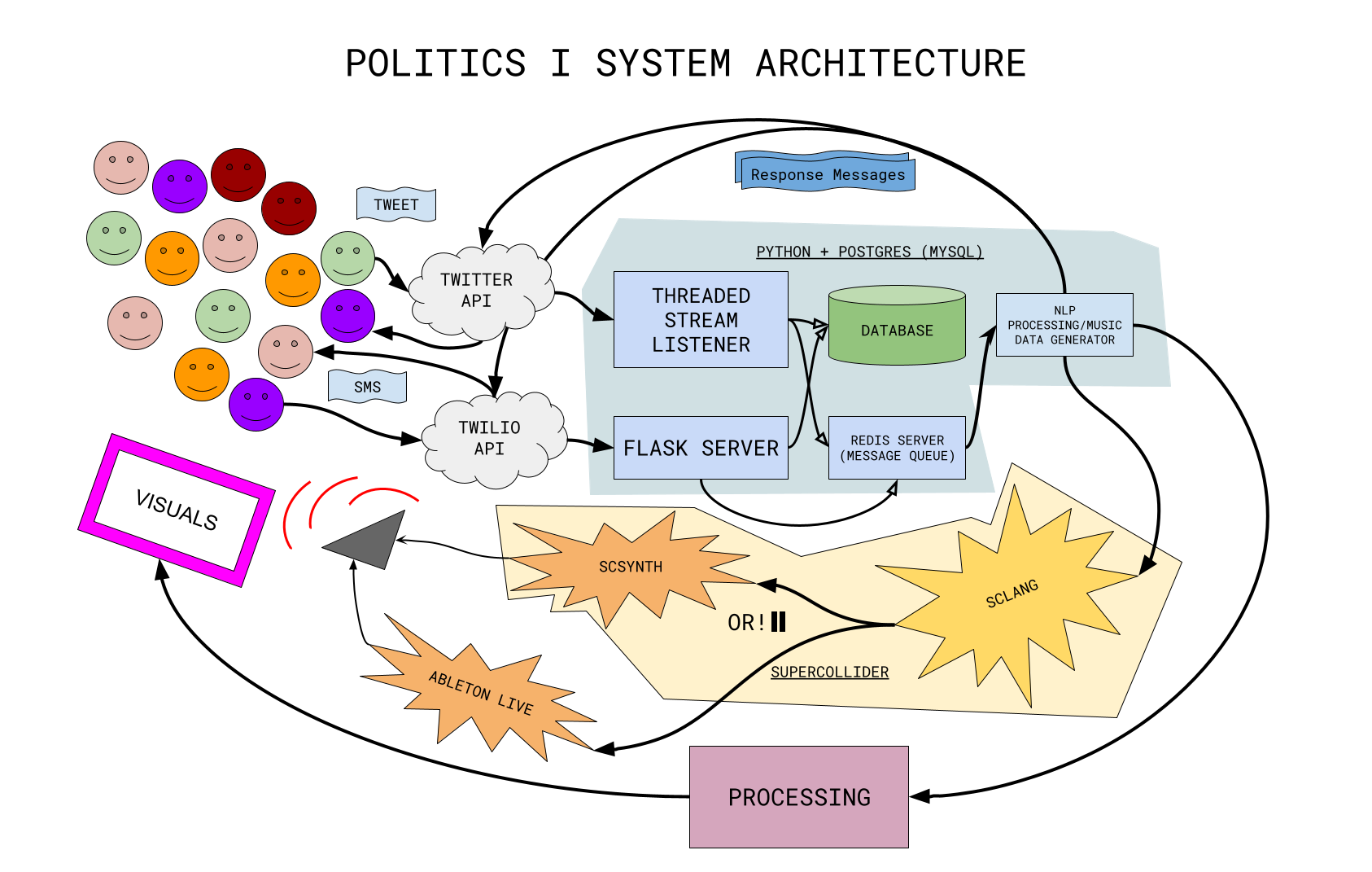
Messaging & The Cloud
The system architecture uses web endpoints and the APIs of messaging servicer Twilio and social media company Twitter. These two services route tweets and texts from the audience to the system, and from the system back to users.
Data Processing and Internal Routing
The system takes advantage of a Flask-based framework, a Tweepy stream listener, a PostgreSQL database system, a Redis server to handle incoming messages and store them, and Socket.IO for live communication between the messaging side and the data processing and music generation side of the system.
- Flask is used to receive incoming POST messages (SMS messages) from the Twilio API.
- Tweepy, a Python package for interacting with Twitter’s RESTful API, runs a threaded stream listener to listen to tweets sent from the audience to the system.
- Postgres serves as a storage system for messages submitted during performances, which can then be used for analysis, further development, and debugging.
- The Redis server is essentially a message queue that allows me to handle messages incoming from both Twilio and Twitter in a thread-safe manner. While a Redis server more powerful than necessary, when something like a threading.Queue would probably suffice, Flask provides easy, out-of-the-box deployment.
- The Redis server forwards all messages incoming over to a Socket.IO client, where the music generator digests messages, converts them into sound, and sends message responses back to the audience.
Sound Synthesis Engine
Sound synthesis currently occurs through a mix of Ableton’s Live and SuperCollider. In some cases, SuperCollider operates as an advanced language for MIDI sequencing. In other cases, it conducts all of the sound synthesis itself
Visuals
Visualization is written in Java through the software sketchbook and language Processing.
Internal Communication
Internal communication occurs entirely through Open Sound Control (OSC)
Installation
Politics I requires many different dependencies. These installation instructions will walk users through downloading and installing the software required for Politics I. Users can also find the instructions on the Github repository here: https://github.com/eclemmon/politics_1
NB: Politics I has only been tested and run on MacOS. All installation instructions are based on the assumption that you are running MacOS Monterey.
Piecewise
Download and install Python 3.9.2
Download and install SuperCollider 3.12.2
Download and install Ableton Live 11
Download and install Twilio CLI interface
Download and install ngrok CLI interface
Download and install Postgresql
Download and build Redis from source
Download and extract Politics I code base from Github
With Brew
Still install Python 3.9.2 manually
Install Brew by Opening Terminal
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Install All Packages
brew install \
--cask supercollider \
ngrok/ngrok/ngrok \
git \
postgresql \
redis &&
brew tap twilio/brew && brew install twilio
Clone Politics I code base from Github
git clone https://github.com/eclemmon/politics_1.gitNext Steps:
Signing up for Twilio, low-cost, enterprise messaging service provider:
Fill Twilio account as needed (takes < $20 to buy the number and fill the account for a concert depending on the number of people in the audience).
Signing up for Twitter, and creating a free developer account, so that you can send tweets and listen to tweet streams with the python package Tweepy:
Create a dev account and go through the process of applying for a standalone app.
Critical for replying to tweets automatically with the Politics I app, is to have OAuth turned on:
Setting up Postgresql:
Follow the instructions below. You can name the database whatever you want, but it is recommended that it is labeled something recognizably associated with the piece, like politics_1_prod
Setting up Python:
Initialize your python virtual environment:
python3 -m venv /path/to/new/virtual/environmentActivate your python virtual environment:
source myvenv/bin/activateInstall required Python packages:
python3 -m pip install -r requirements.txtSetting Environment Variables:
Create a .env file:
touch .envThis is the list of variables that need to be assigned in the .env file:
# GET THESE TWILIO VALUES FROM TWILIO DASH
TWILIO_ACCOUNT_SID=
TWILIO_AUTH_TOKEN=
TWILIO_PHONE_NUMBER=
# GET THESE TWITTER VALUES FROM TWITTER DEV DASH
TWITTER_CONSUMER_KEY=
TWITTER_CONSUMER_SECRET=
TWITTER_ACCESS_TOKEN=
TWITTER_ACCESS_SECRET=
# YOUR TWITTER HANDLE GOES HERE, AUDIENCE MEMBERS SHOULD BE INSTRUCTED TO TWEET AT YOUR ACCOUNT
SEARCH_TERM=
# SOME LOGIC VALUES FOR RUNNING THE PROGRAM
MOVEMENT=1
SCORED=false
DAW=true
DEBUG=false,
SECRET_KEY=abc123
# SHOULD BE THE NAME OF THE POSTGRES DB YOU CREATED
SQLALCHEMY_DATABASE_URI=postgresql:///politics_1_prodTwilio SID and Auth token instructions
Instructions for finding and getting twitter authentication keys and secrets.
Once all these variables are set, you should be almost ready to go!
First boot the messaging servicers:
sh run.shThen, open Live and Supercollider (whether you open live will depend on the movement you are performing) and execute any necessary SuperCollider code in the movement_name_main.scd file. Then navigate back to the directory of the movement you are performing and execute:
sh run_movement_name.shCode Base
git clone https://github.com/eclemmon/politics_1